Introduction
Considéré comme l’un des grands défis informatiques de notre décennie, l’émergence du Big Data est souvent estimée comme l’une des innovations technologiques les plus significatives.
Selon l’édition 2019 du Statista Digital Economy Compass, 33 zettaoctets (Zo) de données, soit 2.64e+14 gigabits (Gb), auraient été créées dans le monde l’année dernière. Si vous avez du mal à vous représenter un tel volume, c’est tout à fait normal. Peut-être que l’infographie suivante pourrait vous éclairer.

Fig 1. Volume de données stocké au cours de l’année 2018 (Source: Statista Digital Economy Compass 2019)
Le big data répond donc à la question suivante: Comment traiter des données massives ?
Bien que nous ayons aujourd’hui à notre disposition des machines dont la puissance en matière de CPU, RAM et GPU ne cesse de croître, la quantité de données évolue plus rapidement que les capacités des ordinateurs à traiter ces données. C’est pourquoi de nouvelles solutions ont dû émerger afin de répondre à cette problématique. La réponse fut le “parallel computing”. En effet, si une machine s’avère insuffisante pour faire face à ces données massives, alors plusieurs y parviendront.
Comme son nom l’indique, le “parallel computing” consiste à tout simplement à répartir le travail entre plusieurs machines et l’exécuter simultanément. La logique est évidente, plutôt que de faire peser toute la charge sur un élément, la répartir entre plusieurs rendra son exécution moins fastidieuse et plus rapide.
De nouvelles technologies ont ainsi vu le jour afin de travailler dans un environnement Big Data. Aujourd’hui, certaines sont très connues du public. On citera notamment le précurseur, Hadoop et son modèle de programmation MapReduce, et bien entendu, Spark. Initié en 2010, soit 4 ans après Hadoop, Spark (Apache Spark) tend aujourd’hui à être le framework leader pour le traitement de données massives car là où Hadoop lit et écrit les fichiers en HDFS (Hadoop Distributed File System) pour traiter la donnée, Spark est plus rapide en utilisant la mémoire vive (RAM) via son concept de RDD ( Resilient Distributed Dataset). Par ailleurs, Spark possède une riche librairie de machine learning (SparkML). Si vous désirez connaître les principales caractéristiques/différences entre Hadoop et Spark, je vous invite à consulter ce lien: Difference Between Hadoop and Spark.
Cette petite introduction sur le Big Data étant faite, nous allons pouvoir plonger au coeur du sujet de cet article, le parallel computing avec Dask.
Présentation de Dask
Qu’est-ce que c’est ?
Si vous deviez retenir une chose dans cet article, cela serait sans doute le paragraphe suivant:
Elaboré par Matthew Rocklin (2015), Dask est une librairie écrite en Python qui, comme Hadoop et Apache Spark, permet de traiter des données massives en exploitant le parallel computing. À ce stade, vous seriez tenté de vous demander quel serait l’intérêt d’utiliser Dask sachant qu’il existe déjà des frameworks open source reconnus, validés par une large communauté et utilisés dans le monde. La réponse est relativement simple, Dask exploite le potentiel de librairies bien connues dans le milieu de la data tels que Numpy, Pandas, Scikit-Learn. En s’appuyant sur ce riche écosystème, Dask permet de réaliser du traitement de données distribué en copiant ces librairies, avec aucune, voir peu de modifications de code à réaliser. Qui plus est, Dask bénéficie du soutien des communautés de cet écosystème, ce qui contribue fortement à son développement.
Pourquoi Dask ?
Si l’on regarde la 2020 Developer Survey de Stack Overflow, on peut constater que Python est l’un des langages de programmation les plus utilisés dans le monde chez les developpeurs (44.1 %) juste derrière JavaScript (Web), HTML/CSS (Web) et SQL (base de données). De ce fait, Python est le langage dominant en matière de programmation générale et à destination de la data.
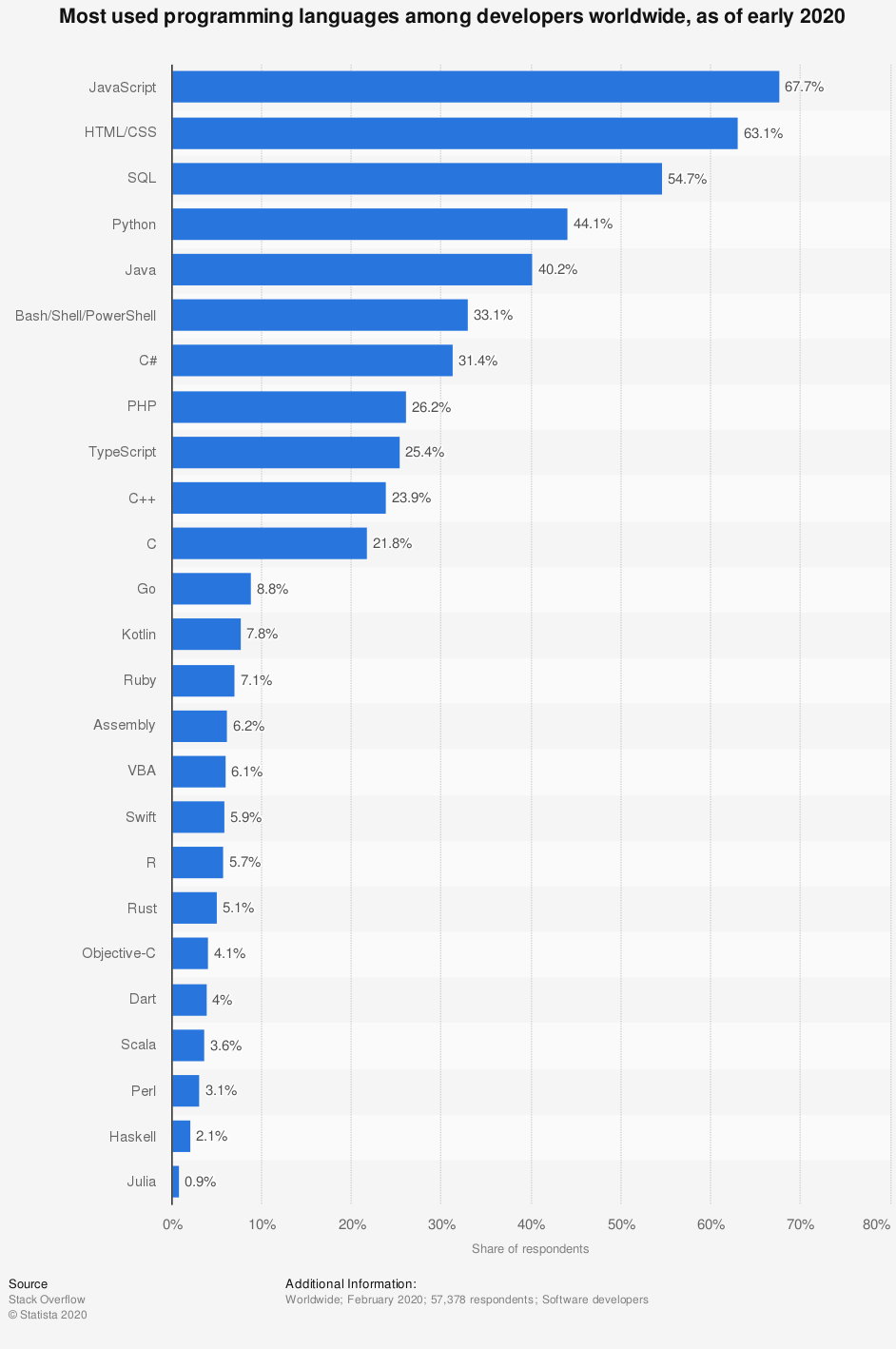
Fig 2. Langages de programmation les plus utilisés dans le monde en 2020 (Source: Stack Overflow 2020 Developer Survey)
Il est évident que la simplicité de la syntaxe de Python ainsi que le développement de nombreuses librairies telles que Numpy, Pandas, Matplotlib, Scikit-learn, Tensorflow-Keras, en parallèle de l’engouement massif pour l’A.I et la data de manière générale, ont contribué à sa popularité. En temps normal, si l’on travaille avec un volume de données “convenable”, utiliser ces librairies ne pose aucun problème, mais les choses se compliquent dès lors que la quantité de données devient conséquente pour une seule machine. En effet, les librairies citées précédemment n’ayant pas été créées pour être scalable (appliquées à une large quantité de données), travailler dans un environnement Big Data devient une tâche laborieuse voire impossible. Une solution serait donc d’utiliser les frameworks tels que Hadoop ou Spark pour réaliser du calcul distribué. Cela implique au préalable de connaitre le fonctionnement du framework, son API et parfois la réécriture du code dans un autre language. Effectivement, si l’on veut tirer pleines performances de Spark il faudrait que le code soit écrit en Scala et non pas en Python dans la mesure où Scala est 10x plus rapide que python pour le traitement et l’analyse de données. Ce processus pouvant être fastidieux et frustrant, il serait préférable de travailler avec les librairies scalées propres à Python. C’est exactement ce que va nous permettre Dask.
Dask va scaler Numpy, Pandas et Sckikit-learn en clonant leur API afin de fournir un environnement familier et réduire au maximum la réecriture du code (Note: Il est important de noter que même si Dask copie les API des librairies data les plus connues de Python, il n’implémente pas encore aujourd’hui tous leur contenu).
Comment Dask fonctionne ?
Concepts
Pour comprendre le parallel computing avec Dask, il faut savoir de quoi est constitué un réseau distribué Dask. Pour cela, 3 concepts fondamentaux sont à retenir:
- Le scheduler:
Comme son nom l’indique, le rôle du scheduler est de planifier, distribuer les tâches (C’est en quelque sorte le chef d’orchestre ou le manager). Ce dernier assimile les tâches à effectuer sous la forme de graph (Task graph) et demande ensuite aux workers de réaliser ces tâches.
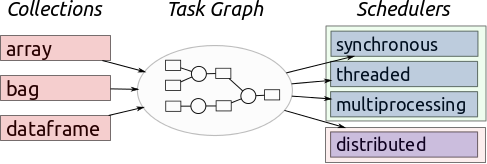
Fig 3. Rôle du Scheduler
- Le client:
Le client est ce qui va nous permettre de nous connecter au réseau distribué Dask. Après avoir créé le réseau, on initialise le client en lui passant l’adresse du scheduler. Le client s’enregistre en tant que scheduler par défaut et permet d’exécuter toutes les collections de Dask (dask.array, dask.bag, dask.dataframe et dask.delayed).
- Les Workers:
Si l’on décide d’utiliser dask sur une seule machine (local), les workers sont les coeurs du processeur tandis que dans un cluster ce sont les différentes machines. Les workers reçoivent les informations du scheduler et exécutent les tâches. Ils rapportent au scheduler lorsqu’ils ont terminé et stockent les computations réalisées.
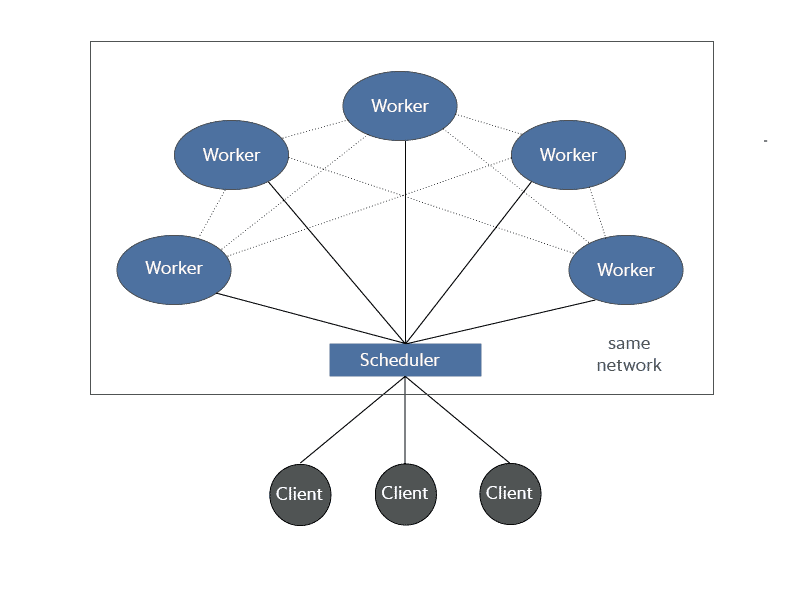
Fig 4. Exemple de reseau distribué Dask avec 3 clients et 5 workers ( Les lignes entre les workers indiquent qu’ils communiquent entre eux)
Implémenter un réseau distribué
Dask propose 2 options pour réaliser du calcul distribué. La première étant de scaler le travail entre plusieurs machines (On parle de cluster). L’autre possibilité étant de rester dans un environnement local dans lequel Dask va distribuer les computations entre les coeurs du processeur d’une seule machine. Créer un cluster n’est pas forcément la meilleure décision pour traiter des données massives. D’une part, les ordinateurs actuels permettent avec Dask de travailler avec des jeux de données de plus de 100 gb. D’autre part, travailler en local évite bon nombre de contraintes telles que le fait d’être limité par la bande passante, mais aussi le fait de devoir gérer des images docker plutôt que de travailler avec un software environment local par exemple.
Nous allons maintenant voir comment implémenter simplement les deux cas de figure cités précédemment:
- Dask Distributed Local:
# We import Dask Client
from dask.distributed import Client
# Initializing the Client without parameters
client = Client()
# or
client = Client(processes=False)
print('Dashboard:', client.dashboard_link)
Client
Scheduler: tcp://127.0.0.1:39663
Dashboard: http://127.0.0.1:8787/status
Cluster
Workers: 4
Cores: 8
Memory: 16.51 GB
Et voila, nous venons de créer un réseau distribué local ! On notera le fait que Dask renvoit l’adresse du scheduler ainsi que les caractéristiques du réseau (Note: Il est tout à fait possible de faire varier le nombre de workers).
- Dask Distributed cluster:
# We have to creat a software environment that's gonna be run as a docker image on all workers in the cloud
# Workers and Client NEED to have same packages versions
import coiled # We import coiled which makes it easy to scale on the cloud
# I created a software environment made up of all the packages I need (e.g: scikit-learn, XGBoost, Dask-ML,...)
# A docker image is created and can be reused
coiled.create_software_environment(
name="ml-env",
conda="environment.yml",
)
coiled.create_cluster_configuration(
name="ml-env",
software="ml-env",
# there are other inputs here you can also adjust
)
#Using our previous software environment on a docker image, we creat a cluster with 10 workers and initialize the client
cluster = coiled.Cluster(n_workers=10,
software="new_ml_env")
from dask.distributed import Client
client = Client(cluster)
print('Dashboard:', client.dashboard_link)
Client
Scheduler: tls://ec2-18-218-215-162.us-east-2.compute.amazonaws.com:8786
Dashboard: http://ec2-18-218-215-162.us-east-2.compute.amazonaws.com:8787
Cluster
Workers: 10
Cores: 40
Memory: 171.80 GB
Le code présenté ci-dessus permet de créer un cluster dans le cloud. Pour y parvenir nous avons utilisé Coiled Cloud qui permet de scaler très simplement dans le cloud AWS en évitant de se soucier de la configuration du cluster. Actuellement en Beta, Coiled est gratuit. Très prometteur, je vous invite grandement à l’essayer.
Petites précisions concernant le cluster, il faut tout d’abord créer une image docker qui contient l’ensemble des packages nécessaires pour le projet. L’image sera ensuite runnée sur chaque workers au moment de la création du cluster (Note: Chaque workers, ainsi que le client doivent posséder les mêmes dépendances sous risque de poser des problèmes par la suite). Dès lors que le cluster est créé, on initialise le client en lui passant le cluster en paramètre. Comme indiqué ultérieurement, Dask renvoit l’adresse du scheduler ainsi que les caractéristiques du cluster.
Vous l’aurez sous doute remarqué, Dask renvoit également l’adresse du “dashboard”. Le dashboard est un outil très utile puisqu’il permet notamment de comprendre et suivre comment Dask processe les computations, comment elles sont réparties, mais aussi connaître les capacités utilisées de chaque workers.
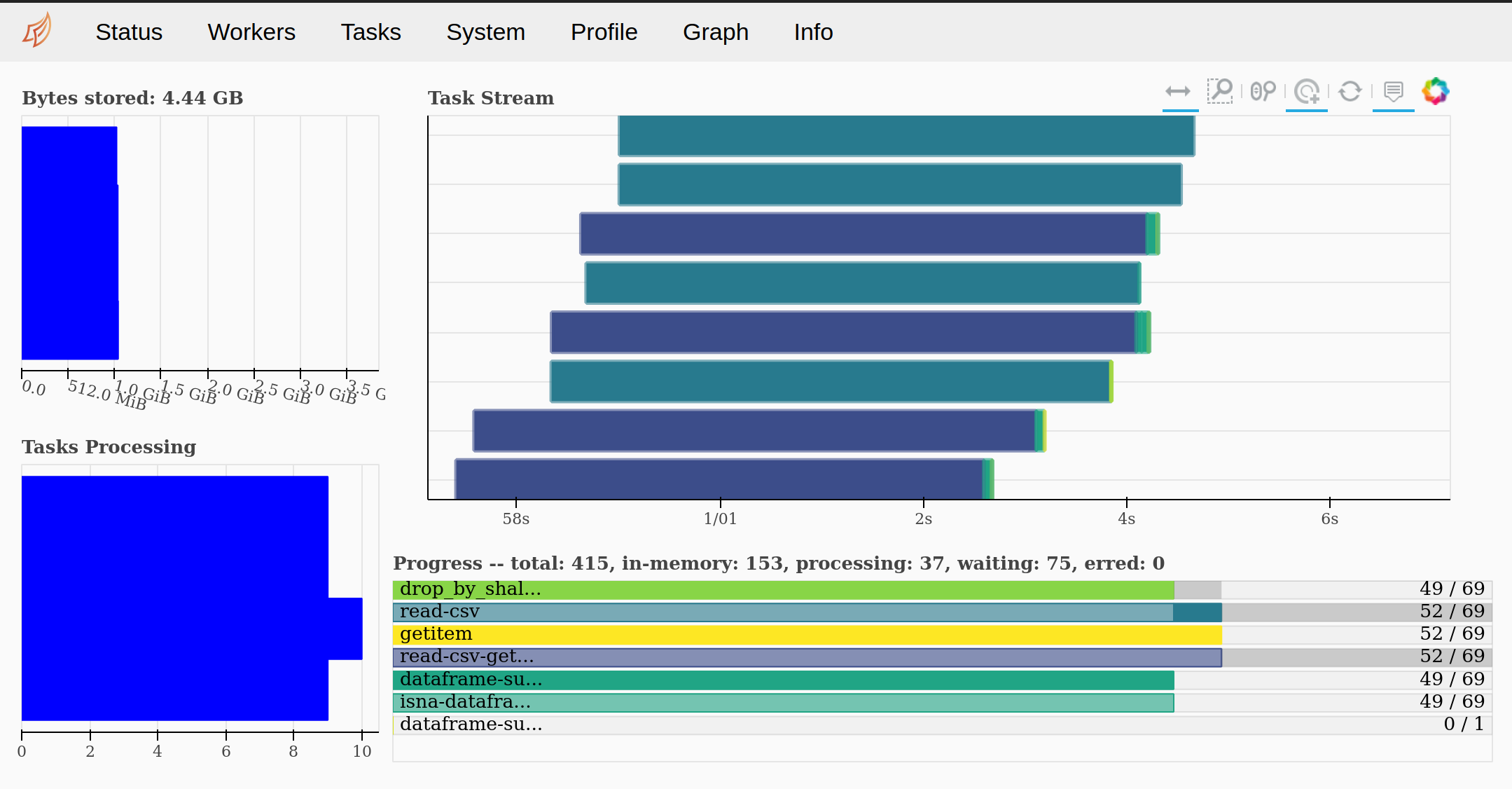
Fig 5. Dask Dashboard
Pour en savoir plus sur le dashboard, je vous invite à consulter la vidéo ci-dessous:

Dask API
Dask est composé de plusieurs API:
- Arrays (S’appuye sur NumPy)
- DataFrames (Repose sur Pandas)
- Bag (Suit map/filter/groupby/reduce)
- Dask-ML (Suit entre autre Scikit-Learn)
- Delayed (Couvre de manière générale Python)
Puisque ce sont les API que nous sommes le plus susceptible d’utiliser pour la data science, voyons plus en détails Dask.array, Dask.dataframe et pour finir Dask-ML.
Dask arrays
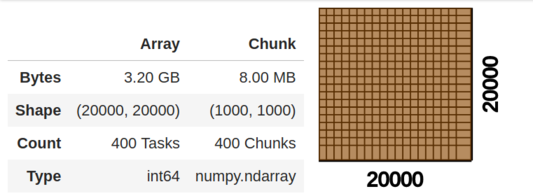
Les Dask arrays coordonnent de nombreux Numpy arrays, disposés en “chunks” (morceaux) à l’intérieur d’une grille. L’API de Dask prend en charge un large partie de l’API Numpy.

Fig 6.Repésentation d’un Dask array
- Dask.array en action:
import dask.array as da
x = da.random.randint(1, 100, size=(20000, 20000), # 400 million element array
chunks=(1000, 1000)) # Cut into 1000x1000 sized chunks
y = x.mean()
x
y.compute()
49.99919512
Si vous êtes familier avec Numpy vous aurez constaté que la seule différence réside uniquement dans l’importation de dask.array plutôt que celle de Numpy. Si l’on cherche à afficher l’objet x on constate qu’il n’apparaît pas comme le ferait un objet Numpy, mais au lieu de ça, s’affiche les propriétés de l’objet Dask. Dask étant par défaut “lazy”, il ne réalise pas la computation tant qu’elle n’est pas explicitement demandée par la méthode .compute() (Note: Utiliser la méthode .compute() va stocker la computation en mémoire. La méthode doit être appelée si la computation à suffisamment de place sous peine de voir l’erreur KilledWorker).
Dask dataframe
Les Dask dataframes permettent de coordonner plusieurs dataframes Pandas partitionnés selon l’index. De même que l’API Dask.array, Dask.dataframe possède une grande partie des fonctionnalités de l’API Pandas.
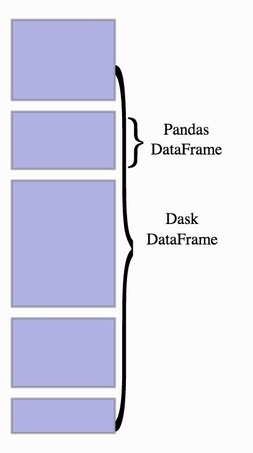
Fig 7. Repésentation d’un Dask dataframe
- Dask.dataframe en action:
import dask.dataframe as dd
df = dask.datasets.timeseries()
df

df.head()
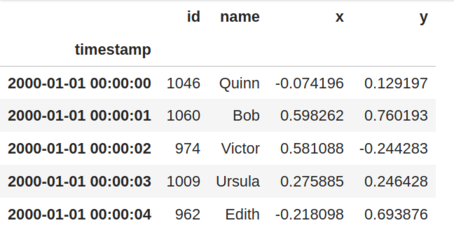
x_mean_by_name = df.groupby('name')['x'].mean()
x_mean_by_name
Dask Series Structure:
npartitions=1
float64
...
Name: x, dtype: float64
Dask Name: truediv, 101 tasks
x_mean_by_name.compute()
name
Alice -0.000354
Bob -0.001484
Charlie -0.001285
Dan 0.003877
Edith -0.000339
Frank 0.000321
George -0.002556
Hannah -0.001059
Ingrid -0.000804
Jerry -0.002137
Kevin 0.001354
Laura 0.000851
Michael -0.000793
Norbert 0.001598
Oliver -0.002574
Patricia -0.001985
Quinn -0.000443
Ray -0.000632
Sarah -0.002952
Tim 0.000621
Ursula 0.003599
Victor 0.004504
Wendy -0.001640
Xavier 0.001189
Yvonne -0.001253
Zelda -0.002810
Name: x, dtype: float64
Pas de grand changement par rapport à Dask.array. Si l’on cherche à afficher un dataframe, Dask le renvoie sous le format “lazy” (sans les valeurs). On peut cependant afficher un partie du dataframe avec .head() et si l’on désire réaliser une computation, on utilise comme vu précédemment la méthode .compute() (Note: Connaître le nombre de partitions est important pour bon nombre d’opérations, par exemple avec .concat(), dans la mesure où les dataframes doivent avoir le même partitionnage).
Dask-ML
Comme son homologue Spark ML, Dask-ML permet de réaliser du machine learning distribué. L’API repose sur celle de Scikit-learn et d’autres, tel que XGBoost. De manière générale, l’API peut être utilisée pour du preprocessing, réaliser de la cross validation, faire de l’hyperparameters search, créer des pipelines et autres.
Dask-ML peut etre utilisée pour pallier à 2 types de contraintes. La première étant celle de la mémoire (Memory-Bound), et la deuxième étant d’origine computationelle (CPU-Bound).
 Fig 8.Dimensions of scale
Fig 8.Dimensions of scale
Memory-Bound
Ce problème se pose lorsque la taille du jeu de données est supérieure à la RAM. Prenons un exemple concret pour comprendre le problème. Le dataset Microsoft Malware Prediction, challenge Kaggle d’il y a 2 ans, comporte approximativement 10M de lignes et 80 colonnes. Il est tout à fait possible de lire le dataset avec Pandas bien que cela soit beaucoup plus “challenging” qu’avec Dask, mais imaginons que l’on veuille préprocesser les données…là, ça risque de coincer. Par exemple, utiliser un One-Hot Encoder sur les variables catégorielles ferait exploser la taille du jeu de données et ne tiendrait certainement pas dans la RAM (sauf si vous avez un super-ordinateur). L’extrait de code ci-dessous permet de préprocesser le jeu de données sans grandes difficultés grâce à Dask-ML (Note: Vous remarquerez que le code est identique à celui de Scikit-Learn).
import dask.array as da
import dask.dataframe as dd
from sklearn.pipeline import Pipeline
from dask_ml.compose import ColumnTransformer
from dask_ml.preprocessing import StandardScaler, OneHotEncoder
from dask_ml.impute import SimpleImputer
binary_processor = Pipeline(steps=[('imputer',SimpleImputer(strategy='most_frequent'))])
numerical_processor = Pipeline(steps=[('imputer',SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_processor = Pipeline(steps=[('encoder',OneHotEncoder())])
#category_processor = Pipeline(steps=[('encoder',TargetEncoder(cols=category_columns))])
preprocessor = ColumnTransformer(transformers=
[('bin',binary_processor,binary_columns),
('num',numerical_processor,numerical_columns),
('cat',categorical_processor,category_columns)])
X_train_processed = preprocessor.fit_transform(X_train)
CPU times: user 8.09 s, sys: 101 ms, total: 8.19 s
Wall time: 3min 10s
CPU-Bound
Ce cas de figure apparaît lorsque le modèle ML créé est si large, complexe que cela à un impact sur le flux de travail (e.g.une tâche d’apprentissage, recherche d’hyperparamètres beaucoup trop longue). Dans ce contexte, paralléliser la tâche à effectuer en utilisant les estimateurs de Dask-ML permet de faire face à ces difficultés. L’extrait ci-dessous montre comment mener une hyperparameters search via Dask-ML et son estimateur HyperbandSearchCV.
import numpy as np
from dask_ml.model_selection import HyperbandSearchCV
from dask_ml.datasets import make_classification
from sklearn.linear_model import SGDClassifier
X, y = make_classification(chunks=20)
est = SGDClassifier(tol=1e-3)
param_dist = {'alpha': np.logspace(-4, 0, num=1000),
'loss': ['hinge', 'log', 'modified_huber', 'squared_hinge'],
'average': [True, False]}
search = HyperbandSearchCV(est, param_dist)
search.fit(X, y, classes=np.unique(y))
search.best_params_
{'loss': 'log', 'average': False, 'alpha': 0.0080502}
Différences avec Spark
Parut en 2010, grâce à son efficacité et son intégration dans un riche écosystème (Apache projects), Spark est aujourd’hui incontournable pour travailler dans un environnement Big Data. Développé plus tardivement, Dask est un projet plus léger que Spark. Grâce à son intégration dans l’écosystème Python (Numpy, Pandas, Scikit-Learn, ect…), Dask permet de réaliser des opérations plus complexes que Spark. Comparer Spark et Dask afin de déterminer lequel est meilleur n’aurait pas vraiment de sens puisque leur utilisation dépend avant tout de ce que l’on cherche à réaliser. Par ailleurs, Dask et Spark peuvent très bien être utilisés ensemble sur un même cluster. Nous allons toutefois dresser quelques différences notables entre les deux technologies.
-
Langage:
- Comme nous l’avons mentionné plus haut, Spark est codé en Scala mais supporte également Python et R (Scala reste le langage offrant la meilleure synergie avec Spark).
- Quant à Dask, il est codé en Python et ne supporte uniquement que ce langage.
-
Ecosystème:
- Spark fait partie de l’écosystème Apache et est de ce fait bien intégré à de nombreux autres projets (e.g. Hadoop/Hive, HBase, Cassandra, etc…).
- Dask est intégré dans l’écosystème Python et a été crée pour scaler les librairies data les plus connues (e.g. Numpy, Pandas, Scikit-Learn).
-
Âge:
- Développé en 2010, Spark est aujourd’hui dominant dans le milieu Big Data.
- Plus jeune (crée en 2014), Spark est en constante amélioration afin de rendre l’expérience la plus similaire aux librairies data sous Python.
-
Champ d’application:
- Spark se concentre davantage sur l’aspect business intelligence, analytics, en permettant de faire de la requête de données via SQL et du machine learning “léger”.
- Dask est plus adapté pour des applications scientifiques ou business nécéssitant du machine learning plus poussé.
-
Design:
- Le modèle interne de Spark est de niveau supérieur, offrant de bonnes optimisations de haut niveau sur des calculs appliqués uniformément, mais manquant de flexibilité pour des algorithmes plus complexes ou des systèmes ad hoc. Il s’agit fondamentalement d’une extension du paradigme Map-Shuffle-Reduce.
- Le modèle interne de Dask est de niveau inférieur et manque donc d’optimisations de haut niveau, mais il est capable d’implémenter des algorithmes plus sophistiqués et de construire des systèmes sur mesure plus complexes. Il est fondamentalement basé sur une planification générique des tâches.
-
Scaling:
- Tout comme Spark, Dask permet de créer des clusters composés jusqu’à mille machines.
Si vous hésitez entre Spark et Dask, ceci devrait vous aider:
-
Les raisons pour lesquelles vous devriez choisir Spark:
- Vous préférez utiliser Scala ou SQL.
- Vous disposez principalement d’une infrastructure JVM et de systèmes hérités.
- Vous voulez une solution de confiance, largement utilisée dans le milieu de l’entreprise.
- Vous faites de la business analytics ou vos applications nécéssitent du Machine learning peu complexe.
- Vous avez besoin d’une solution tout-en-un (ecosystème Apache).
-
Les raisons pour lesquelles vous devriez choisir Dask:
- Vous préférez tiliser Python et êtes déjà familier avec ses librairies.
- Vous avez des projets plus complexes que ce que Spark permet de résoudre.
- Vous souhaitez une transition plus légère d’une utilisation locale à une utilisation en cluster.
- Vous voulez interagir avec d’autres technologies et installer plusieurs paquets ne vous dérange pas.
Conclusion
Cet article touche malheureusement à sa fin. Dask est une librairie très riche à parcourir, qui au premier abord semble très facile d’accès mais qui nécessite du temps pour être maitrisée. L’objectif de cet article était avant tout de vous introduire au parallel computing avec Dask. Nous avons vu comment et pourquoi cette librairie pouvait être utile, son fonctionnement, ainsi que les API les plus importantes pour la data analyse et science. Pour finir, nous avons également traité des principales différences entre Dask et Spark.
Je suis convaincu qu’avec le temps Dask sera amené à se développer davantage et à être de plus en plus utilisé dans le monde de l’entreprise tant cette librairie se distingue par sa simplicité. Par ailleurs, développer des outils tels que Dask est essentiel afin de rendre le Big Data plus accessible tant sa place est considérable dans nos sociétés contemporaines.